Chapter 7 n-step Bootstrapping¶
The pseudo code for n-step TD is shown below.
Given a policy, this algorithm will estimate the state values in the environment.

IntroRL implements the above pseudo code with the class NStepTDWalker
Figure 7.2 Random Walk¶
Figure 7.2 illustrates the fact that an n-step algorithm can outperform both TD(0) and Monte Carlo.
For the 19 state random walk process, the image below compares the results of the NStepTDWalker from IntroRL with the published Sutton & Barto values.
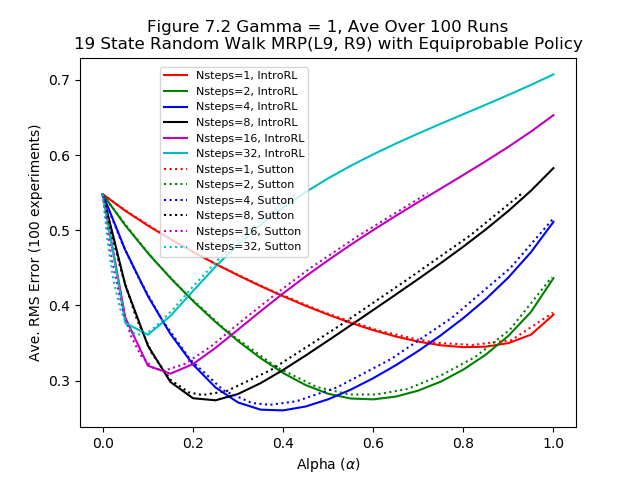
The code used to generate the above figure is: Figure 7.2 Code
Few Examples¶
Chapter 7 gives very few examples against which to verify IntroRL routines.
Perhaps of interest, however, is the use of the n-step Sarsa routine.

Using the above pseudo code, IntroRL implements NStepSarsaWalker for evaluating a policy.
Also implemented is
NStepSarsaQStarFinder
for calculating the optimum action value function Q*.